All the database work we've done hasbeen with a single database table. The majority of databases you'll work withas a developer will have more than one table, and those tables will beconnected together in various ways to form table relationships. In this articlewe'll explore the reasons for having multiple tables in a database, look at howto define relationships between different tables.
Normalization
At this point, our users table doesn'tneed to hold that much data for each user in our system. It stores a name forthe user, whether their account is enabled or not, when they last logged in,and an id to identify each user record. In reality, the requirements of ourapplication will mean that we need to store a lot more data than that. OurSoftware application will be used to manage a library of SQL books and allowusers to check out the books and also review them.
To implement some of theserequirements we could simply try adding more columns to our users table; theresulting table might look a little like this:

Wow, that's a lot of information allin one table! There are other issues here as well, such as duplication of data(often referred to as 'redundancy'). For each book that a user checks out, wehave to repeat all of the user data in our table. It's a similar story with thebook data, if more than one person checks out a book, such as with 'My SecondSQL Book', we have to repeat the book title, author, isbn, and published date.
Duplicating data in this way can leadto issues with data integrity. For example what if for one of the 'My SecondSQL Book' checkouts the title is entered as 'My 2nd SQL Book' instead, or atypo had been made with the isbn on one of the rows? From looking at the datain the table, how would we know which piece of data is correct?
How do we deal with this situation?The answer is to split our data up across multiple different tables, and createrelationships between them. The process of splitting up data in this way toremove duplication and improve data integrity is known as normalization.
For now there are two important things toremember:
1. The reason for normalization is toreduce data redundancy and improve data integrity
2. The mechanism for carrying outnormalization is arranging data in multiple tables and defining relationshipsbetween them
We know that we want to split the datafor our application across multiple tables, but how do we decide what thosetables should be and what relationships should exist between them? Whenanswering questions such as these it is often useful to zoom out and think at ahigher level of abstraction, and this is where the process of database designcomes in.
Database Design
At a high level, the process ofdatabase design involves defining entitiesto represent different sorts of data and designingrelationships between those entities. But what do we mean by entities, andhow do different entities relate to each other? Let's find out.
Entities
An entity represents a real worldobject, or a set of data that we want to model within our database; we canoften identify these as the major nouns of the system we're modeling. For thepurposes of this book we're going to try and keep things simple and draw adirect correlation between an entity and a single table of data; in a realdatabase however, the data for a single entity might be stored in more than onetable.
What entities might we define for our SQL Bookapplication?
1. Well, we already have a user’s table, and we can think of a user as a specific entitywithin our app; a 'user' is someone who uses our app.
2. The purpose of our SQL Book app is to allowusers to use books about SQL, so in this context we can think of books as an entity within our system.
3. One of the things our users can do is to checkout books, so we could have a third entity called checkouts that exists between users and books.
4. We also want users to be able to leave reviewsof books they've read, so we might have another entity called reviews.
5. Finally, we want to store address informationfor each user. Since this address data will only be used occasionally and notfor every user interaction, we decide to store it in a separate table. We couldpotentially still think of this address data as part of the 'users' entity, butfor now let's think of it as a separate entity called addresses.
Now we have defined the entities weneed, we can plan tables to store the data for each entity. Those tables mightlook something like this:
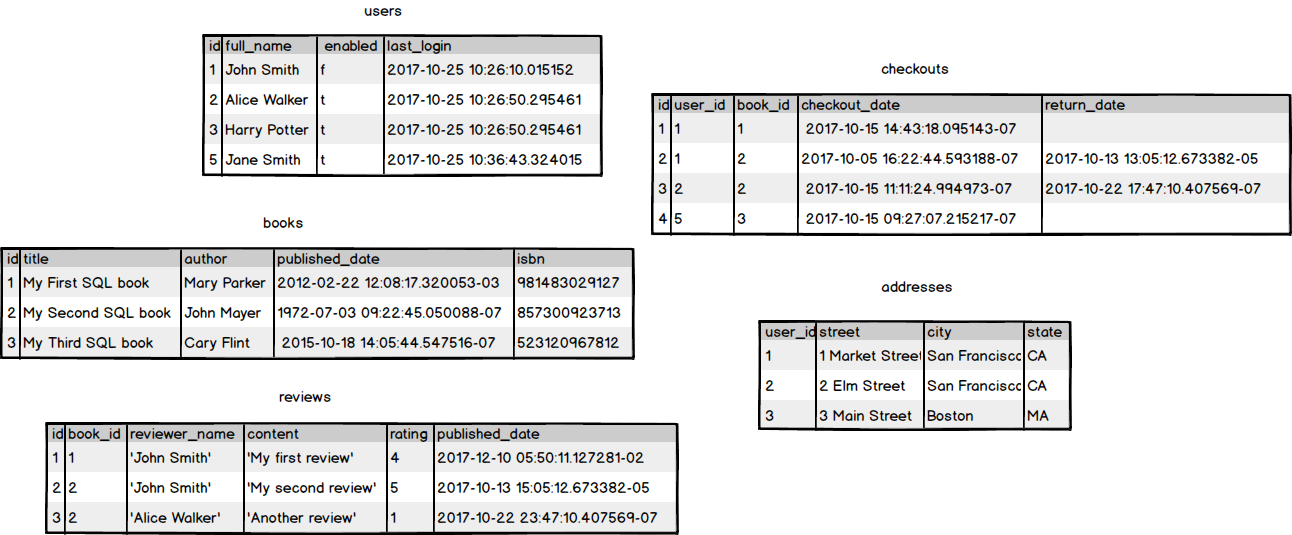
Relationships
We're making good progress with ourdatabase design. We've decided on the entities we want and have formed apicture of the tables we need, the columns in those tables, and even examplesof the data that those columns will hold. There's something missing though, andthat's the relationships between our entities.

If we look at the diagram of our five tables, the tables are allisolated and it's not obvious how these tables should relate to each other.Let's simplify our tables a bit and explicitly define some relationshipsbetween them.
This diagram shows an abstractrepresentation of our various entities and also the relationships between them,(note: in reality we could imaginethat more than one user might share the same address; this structure is intended for illustration purposes). We can thinkof this diagram as a simple EntityRelationship Diagram, or ERD. An ERD is a graphicalrepresentation of entities and their relationships to each other, and is acommonly used tool within database design.
For now it's useful to simply think ofan ERD as any diagram which models relationships between entities.
Keys
Okay, so we now know the tables thatwe need and we've also defined the relationships that should exist betweenthose tables in our ERD, but how do we actually implement those relationshipsin terms of our table schema? The answer to that is to usekeys.
Keys are a special type of constraint used toestablish relationships and uniqueness.They can be used to identify a specific row in the current table, or to referto a specific row in another table. In this article we'll look at two types ofkeys that fulfil these particular roles: PrimaryKeys, and Foreign Keys.
Primary Keys
A necessary part of establishingrelationships between two entities or two pieces of data is being able toidentify the data correctly. In SQL,uniquely identifying data is critical. A Primary Key is a uniqueidentifier for a row of data.
In order to act as a uniqueidentifier, a column must contain some data, and that data should be unique toeach row. in fact, making a column a PRIMARY KEY is essentially equivalent toadding NOT NULL and UNIQUE constraints to that column.
Although any column in a table canhave UNIQUE and NOT NULL constraints applied to them, each table can have only one Primary Key. It is common practice forthat Primary Key to be a column named id.
Being able to uniquely identify a rowof data in a table via that table's Primary Key column is only half the storywhen it comes to creating relationships between tables. The other half of thisstory is the Primary Key's partner, the ForeignKey.
Foreign Keys
A Foreign Key allows us to associate arow in one table to a row in another table. This is done by setting a column inone table as a Foreign Key and having that column reference another table'sPrimary Key column.
The specific way in which a ForeignKey is used as part of a table's schema depends on the type of relationship wewant to define between our tables.
In order to implement that schema correctly itis useful to formally describe the relationships we need to model between ourentities:
1. A User can have ONE address. An address hasonly ONE user.
2. A review can only be about ONE Book. A Bookcan have MANY reviews.
3. A User can have MANY books that he/she mayhave checked out or returned. A Book can be/ have been checked out by MANYusers.
The entity relationships described above canbe classified into three relationship types:
1. One to One
2. One to Many
3. Many to Many
One-to-One
A one-to-one relationship between twoentities exists when a particular entity instance exists in one table, and itcan have only one associated entity instance in another table.
Example:A user can have only one address, and an address belongs to only one user.
This example is contrived: in the real world,users can have multiple addresses and multiple people can live at the sameaddress.
In the database world, this sort ofrelationship is implemented like this: the id that is the PRIMARY KEY of theusers table is used as both the FOREIGN KEY and PRIMARY KEY of the addressestable.
/*
one to one:User has one address
*/
CREATE TABLE addresses (
user_id int, -- Both a primary and foreign key
street varchar(30) NOT NULL,
city varchar(30) NOT NULL,
state varchar(30) NOT NULL,
PRIMARY KEY (user_id),
FOREIGN KEY (user_id) REFERENCES users (id) ON DELETE CASCADE
);
Executing the above SQL statement willcreate an addresses table, and create a relationship between it and the userstable. Notice the PRIMARY KEY andFOREIGN KEY clauses at the end of the CREATE statement. These two clausescreate the constraints that makes the user_idthe Primary Key of the addresses table and also the Foreign Key for the users table.
Let's go ahead and add some data toour table.
INSERT INTO addresses (user_id,street, city, state) VALUES
(1, '1 Market Street', 'San Francisco', 'CA'),
(2, '2 Elm Street', 'San Francisco', 'CA'),
(3, '3 Main Street', 'Boston', 'MA');
The user_id column uses values that exist in the id column of the userstable in order to connect the tables through the foreign key constraint we justcreated.

Referential Integrity
We're going to take a slight detourhere to discuss a topic that's extremely important when dealing with tablerelationships: referential integrity.This is a concept used when discussingrelational data which states that table relationships must always beconsistent. Different RDBMS might enforce referential integrity rulesdifferently, but the concept is the same.
The constraints we've defined for ouraddresses table enforce the one to one relationship we want between it and ourusers table, whereby a user can only have one address and an address must haveone, and only one, user. This is an example of referential integrity. Let'sdemonstrate how this works.
What happens if we try to add another addressfor a user who already has one?
INSERT INTO addresses (user_id,street, city, state)
VALUES (1, '2 Park Road', 'San Francisco', 'CA');
ERROR: duplicate key value violates uniqueconstraint "addresses_pkey"
DETAIL: Key (user_id)=(1) already exists.
The error above occurs because we aretrying to insert a value 1 into the user_id column when such a value alreadyexists in that column. The UNIQUE constraint on the column prevents us fromdoing so.
How about if we try to add an address for auser who doesn't exist?
INSERT INTO addresses (user_id,street, city, state) VALUES
(7, '11 Station Road', 'Portland', 'OR');
ERROR: insert or update on table"addresses" violates foreign key constraint"addresses_user_id_fkey"
DETAIL: Key (user_id)=(7) is not present in table"users".
Here we get a different error. TheFOREIGN KEY constraint on the user_id column prevents us from adding the value7 to that column because that value is not present in the id column of theusers table.
If you're wondering why we can add auser without an address but can't add an address without a user, this is down tothe modality of the relationship between the two entities. Don't worry aboutexactly what this means for now, just think of it as another aspect of entityrelationships.
The ON DELETE clause
You might have noticed in the tablecreation statement for our addresses table, the FOREIGN KEY definition includeda clause which read ON DELETE CASCADE. Adding this clause, and setting it toCASCADE basically means that if the row being referenced is deleted, the rowreferencing it is also deleted. There are alternatives to CASCADE such as SETNULL or SET DEFAULT which instead of deleting the referencing row will set anew value in the appropriate column for that row.
One-to-Many
Okay, time to get back to ourdifferent table relationship types with a look at one-to-many. A one-to-manyrelationship exists between two entities if an entity instance in one of thetables can be associated with multiple records (entity instances) in the othertable. The opposite relationship does not exist; that is, each entity instancein the second table can only be associated with one entity instance in thefirst table.
Example:A review belongs to only one book. A book has many reviews.
Let's set up the necessary data. First let'screate our tables
CREATE TABLE books (
id serial,
title varchar(100) NOT NULL,
author varchar(100) NOT NULL,
published_date timestamp NOT NULL,
isbn char(12),
PRIMARY KEY (id),
UNIQUE (isbn)
);
/*
one to many: Book has many reviews
*/
CREATE TABLE reviews (
id serial,
book_id integer NOT NULL,
reviewer_name varchar(255),
content varchar(255),
rating integer,
published_date timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id),
FOREIGN KEY (book_id) REFERENCES books(id) ON DELETE CASCADE
);
These table creation statements forour books and reviews tables are fairly similar to our previous example.There's a key difference worth pointing out in the statement for our reviewstable however:
Unlike our addresses table, thePRIMARY KEY and FOREIGN KEY reference different columns, id and book_idrespectively. This means that the FOREIGN KEY column, book_id is not bound bythe UNIQUE constraint of our PRIMARY KEY and so the same value from the idcolumn of the books table can appear in this column more than once. In otherwords a book can have many reviews.
Now we have created our books and reviewstables, let's add some data to them.
INSERT INTO books (id, title, author,published_date, isbn) VALUES
(1, 'My First SQL Book', 'Mary Parker', '2012-02-22 12:08:17.320053-03','981483029127'),
(2, 'My Second SQL Book', 'John Mayer', '1972-07-03 09:22:45.050088-07','857300923713'),
(3, 'My First SQL Book', 'Cary Flint', '2015-10-18 14:05:44.547516-07','523120967812');
INSERT INTO reviews (id, book_id,reviewer_name, content, rating, published_date) VALUES
(1, 1, 'John Smith', 'My first review', 4, '2017-12-1005:50:11.127281-02'),
(2, 2, 'John Smith', 'My second review', 5, '2017-10-1315:05:12.673382-05'),
(3, 2, 'Alice Walker', 'Another review', 1, '2017-10-2223:47:10.407569-07');
The order in which we add the data isimportant here. Since a column in reviews references data in books we mustfirst ensure that the data exists in the books table for us to reference.

Just as with the users/ addressesrelationship, the FOREIGN KEY references creates relationships between thereviews table and the books table. Unlike that users/ addresses relationshiphowever, both books and users can have multiple reviews. For example the idvalue of 2 for My Second SQL Book appears twice in the book_id column of thereviews table.
In a real database our reviews tablewould probably also have a Foreign Key reference to the id column in userstable rather than have user type data directly in a reviewer_name column. Weset up the table in this way for our example because we wanted to focus on theone-to-many relationship type. If we had added such a Foreign Key to reviewswe'd effectively be setting up a Many-to-Many relationship between books andusers, which is what we'll look at next.
Many-to-Many
A many-to-many relationship existsbetween two entities if for one entity instance there may be multiple recordsin the other table, and vice versa.
Example:A user can check out many books. A book can be checked out by many users (overtime).

Here, the user_id column in checkoutsreferences the id column in users, and the book_id column in checkoutsreferences the id column in books. Each row of the checkouts table uses thesetwo Foreign Keys to create an association between rows of users and books.
We can see on the first row ofcheckouts, the user with an id of 1 is associated with the book with an id of1. On the second row, the same user is also associated with the book with an idof 2. On the third row a different user, with and id of 2, is associated withthe same book from the previous row. On the fourth row, the user with an id of5 is associated with the book with an id of 3.
Don't worry if you don't completelyunderstand this right away, we'll take a look shortly at what these associationslook like in terms of the data in users and books. First, let's create ourcheckouts table and add some data to it.
CREATE TABLE checkouts (
id serial,
user_id int NOT NULL,
book_id int NOT NULL,
checkout_date timestamp,
return_date timestamp,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE,
FOREIGN KEY (book_id) REFERENCES books(id) ON DELETE CASCADE
);
You may have noticed that our tablecontains a couple of other columns checkout_date and return_date. While thesearen't necessary to create the relationship between the users and books table,they can provide additional context to that relationship. Attributes like acheckout date or return date don't pertain specifically to users orspecifically to books, but to the association between a user and a book.
This kind of additional context can beuseful within the business logic of the application using our database. Forexample, in order to prevent more than one user trying to check out the samebook at the same time, the app could determine which books are currentlychecked out by querying those that have a value in the checkout_date column ofthe checkouts table but where the return_date is set to NULL.
Now that we have our checkoutscreated, we can add the data that will create the associations between the rowsin users and books.
INSERT INTO checkouts (id, user_id,book_id, checkout_date, return_date) VALUES
(1, 1, 1, '2017-10-15 14:43:18.095143-07', NULL),
(2, 1, 2, '2017-10-05 16:22:44.593188-07', '2017-10-1313:0:12.673382-05'),
(3, 2, 2, '2017-10-15 11:11:24.994973-07', '2017-10-2217:47:10.407569-07'),
(4, 5, 3, '2017-10-15 09:27:07.215217-07', NULL);
Let's have a look at what this datalooks like in terms of the relationships between the tables.
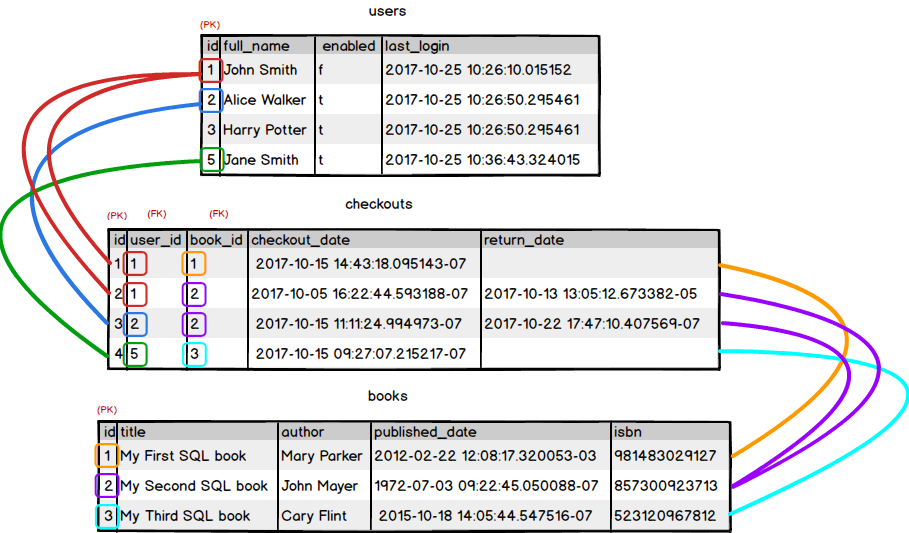
Here we can see that the id value of 1from the users table for 'John Smith' appears twice in the user_id column ofcheckouts, but alongside different values for book_id (1 and 2); this satisfiesthe 'a user can check out many books' part of the relationship. Similarly wecan see that id value of 2 from the books table for 'My Second SQL Book'appears twice in the books_id column of checkouts, alongside different valuesfor user_id (1 and 2); this satisfies the 'a book can be checked out by manyusers' part of the relationship.
We can perhaps think of a Many-to-Manyrelationship as combining two One-to-Many relationships; in this case betweencheckouts and users, and between checkouts and books.